
设计现代数据仓库的方针
如果您的公司正在认真地实施数据报告,将其作为您业务的关键战略资产,那么最终将需要建立一个数据仓库。
因此,要求您为公司建立数据仓库。高效,可扩展且值得信赖的数据仓库。如果您的公司正在认真地实施数据报告,将其作为您业务的关键战略资产,那么最终将需要建立一个数据仓库。
但是,建立数据仓库既不容易也不容易。超过50%的数据仓库项目的接受程度有限,否则将完全失败。
您应该如何开始设计和构建数据仓库?有哪些陷阱,应该如何优化?最重要的是,我应该从哪里开始?
这篇文章提供了有关如何考虑设置数据仓库以避免某些常见陷阱的高级指南。
什么是数据仓库?
现代企业通常将数据存储在不同的位置(数据源)。可以是以下来源的数据:
应用程序数据库:对于初创公司来说,这可能是他们的核心产品应用程序。对于其他企业,这可能是他们的销售点应用程序,
Web应用程序:这可以是扩展业务或维护业务运营所需的应用程序。例如,电子邮件营销软件(例如Mailchimp),网络分析应用程序(例如Google Analytics(分析)或Mixpanel),甚至会计软件(例如Xero和Quickbooks)。
电子表格:可以采用桌面电子表格(Excel,CSV)或在线电子表格(例如Google表格)的形式。这些数据可以由某人手动更新,也可以由Zapier活动更新。
数据仓库将来自不同来源的数据同步到一个地方,以满足所有数据报告需求。
它提供可靠的数据,并可以处理公司所有员工的查询工作量。
设计数据仓库
典型的数据仓库设置如下所示:
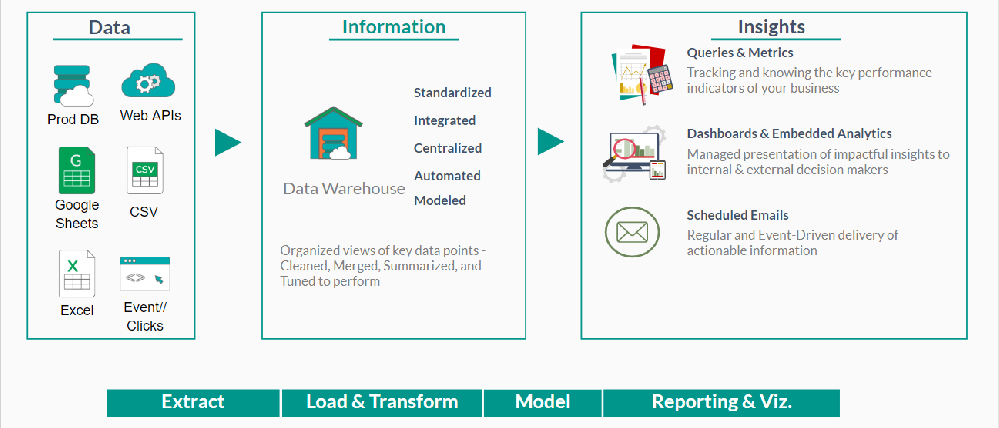
您可以根据报告要求设计和构建数据仓库。确定所需数据后,您可以设计数据以将信息流到数据仓库中。
1.为每个数据源创建一个架构
为您要同步到数据库的每个数据源创建一个数据库架构。
帮助您快速识别每个表所来自的数据源,这随着数据源数量的增加而有所帮助。加入公司的未来数据分析师和业务团队成员还可以快速了解每个数据源的内容。
使您可以为每个数据源分配特定的权限(读/写)。例如,数据工程师可能不想让初级分析人员仅读取特定的架构,而不希望写入特定的架构。
当您的数据源数量随着时间增长时,这特别有用。只需查看数据可能包含的来源数量即可。

例如,您可以设置一个名为mailchimp,的架构xero,或者fbads针对您希望分别从这些应用程序导入到仓库的电子邮件营销,财务和广告数据。
将联系人表从Mailchimp导入数据库时,
可以按以下方式查询它们:
SELECT name, email FROM mailchimp.contacts
如何创建模式
创建模式很容易。您只需要键入一行即可创建新的架构。实际上,在Postgres中只有3个字。
例:
CREATE SCHEMA mailchimp
注1:新分析师可能会对数据库架构感到困惑。有2个架构定义。模式可以用来描述
数据库中的表和字段如何相互关联,或者
数据库表的文件夹,就像文件夹如何组织文件
注意2:mySQL数据库不支持架构,因此您可能要使用命名约定来命名导入的表,例如mailchimp_contacts等。这就是我们鼓励客户将PostgreSQL用于其报告数据库的原因之一。
2.将源数据移入数据仓库
下一步是将源数据同步到数据仓库中。您的工程师可能将此称为ETL脚本。
设计导入脚本时要考虑以下因素:
删除显然不必要的列。如果您以后知道要添加它们,那么添加它们并不难。
重命名列名称,以使其更具描述性或数据库友好性(例如,使用小写或驼峰大写)。
过滤掉明显不必要的记录。这可以记录您的内部用户在生产系统上的测试(有时您的用户可以添加诸如test@yourdomain.com之类的数据,或将其名字设置为测试)
映射记录值以使其更具可读性。这样可以节省您的分析人员稍后在使用CASE-IF进行报告期间重命名它们的工作。例如,某些记录可能会存储数字键(1、2、3、99等)或组织的其余部分可能不知道的缩写名称。在这种情况下,您可能需要在导入过程中将这些键映射到它们的实际值。
导入完成后,将数据库索引应用于目标表。请注意,我们已经在较早的文章中介绍了哪些数据库索引。
错误处理:设置电子邮件//松弛警报消息,当作业失败时,将使用详细的错误日志发送给相关的利益相关者(尤其是数据分析人员)。您可能希望在特定时间段内设置自动重试尝试(或自动恢复过程),以减少这种情况下的误报次数。
3.您是否应该转换源(原始)数据?
我们经常被问到的一个问题是,在将数据移至仓库之前如何应用数据转换。
我们的一般建议是不要这样做。至少不是一开始。特别是如果这是您的第一个数据仓库项目。这有几个原因。
a。您不太可能对数据转换需求有明确的要求
即使给您“明确的要求”,该要求也可能会在项目过程中发生变化或过时。
您将不需要花费时间根据不同利益相关者在不同时间点的需求来修改ETL脚本。
移动(未转换的)源数据可帮助您将ETL脚本的依赖性与“业务需求”分开。
b。您可能需要其他情况的源数据
将您的源数据考虑为可以作为多个派生表派生的交互基础,可以通过沿不同维度进行汇总或将其与其他来源的表联接起来。
请参阅以下示例,了解如何跟踪卖方转换的效果。
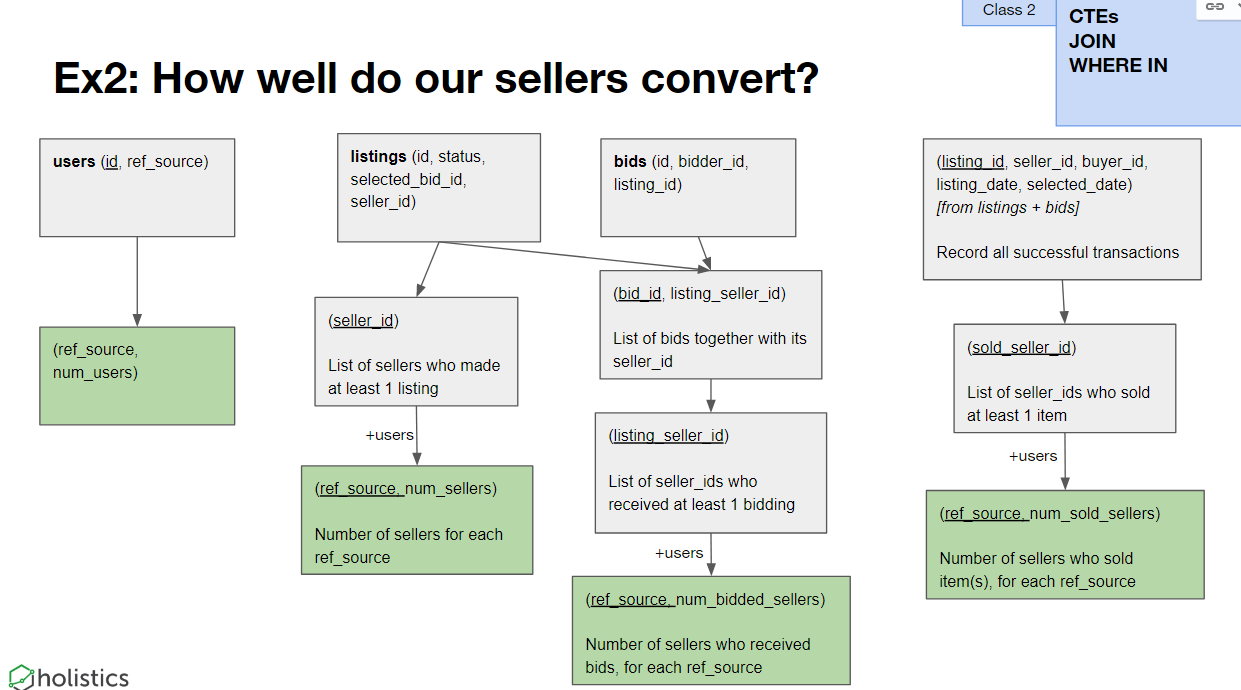
转换数据时,您会丢失源数据中的详细信息,这些信息可能会在以后的报告用例中使用。
例如,当您按时间段汇总销售收入时,您会丢失其他用户可能需要与其他报表关联的特定交易记录的详细信息。
移动未转换的源数据将使您可以灵活地将其与其他数据源结合在一起。
当您开始研究构建可重复使用的数据模型来回答不同的问题时,对源数据的需求变得越来越重要。请参阅以下示例,该同类群组报告是使用一系列事后转换的数据构建的。如果您还没有这样做,这将更加困难
C。减少源系统上的负载
在源系统中运行数据转换可能会占用大量资源,尤其是如果您拥有可为全球客户提供服务的数据库时,尤其如此。
在您移动数据之前,有几种情况可能对您有意义,但这些情况通常适用于已经建立了可靠数据仓库并希望进一步改善数据仓库的公司。
4.转换数据以解决特定问题
关于如何转换数据的思考可能很复杂。如果任其发展,您最终可能会花费大量时间来优化无法为企业带来价值的数据。
没有明确结果的规划,设计和实施数据转换是寻找问题的解决方案。
一个好的经验法则是从结局开始。只能创建数据转换以解决实际用例或报告中的问题。
查找(确定优先级)这些实际用例的好方法是开始使用导入的数据来构建报告和仪表板。
当用户开始提出查询性能问题时,您就可以考虑转换数据了。
这可能是由于以下报告引起的:
(a)包含嵌套子查询或自定义表表达式(CTE)
在迁移之前,您不希望使用长期运行的数据转换作业来使其过载。
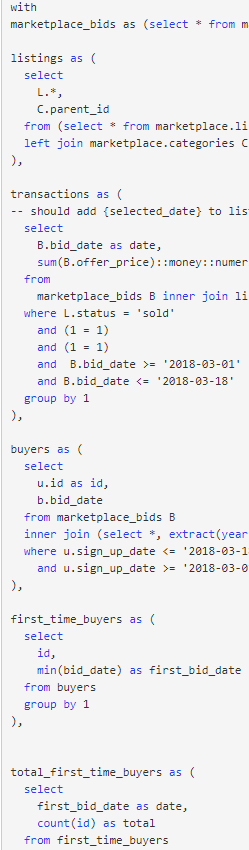
(b)或者在多个表之间具有多个(昂贵的)联接。
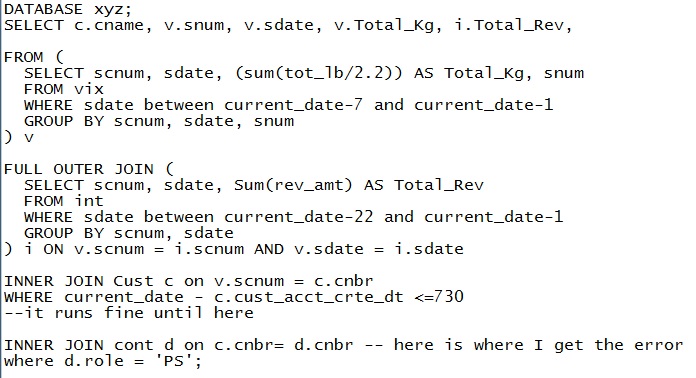
在这里,基于SQL的报表的灵活性非常有用,可以帮助您确定数据转换可以解决的问题。
任何分析师都可以轻松地确定长期运行的查询的根本原因,并开始优化其性能。
这主要是通过自动预聚合数据来完成的。这可以通过实例化视图来完成,您可以在其中创建以下数据转换作业:
聚合大型事务表以加快查询性能。
创建具有来自不同数据源的列的派生表
替换/屏蔽所选用户组的敏感数据。
另一个建议是在数据仓库中创建一个新的数据库架构,以供您存储转换(或后处理)的表。
就像较早的通过模式将每个数据源分开的方法一样,创建特定的模式可以帮助您识别派生/转换的数据表的列表。稍后当您开始对一系列数据导入进行字符串化时,这将很有帮助,随着数据成熟度的增加,数据转换作业将按顺序进行。
5.创建您的内部数据文档
这一点很重要,特别是如果您不希望数据仓库成为黑匣子,只有少数工程师知道如何使用它的话。如果您的用户不理解它,他们将没有信心去查询它。
您可以先创建一个共享文档(可以是Google Doc),该文档描述以下方面的常见知识:
源数据中的表和列,以及如何解释它们
包括数据图(如果有)。
如何阅读报告中的列(仪表盘,指标)及其背后的任何基本假设
每次创建(或更新)报告时,请更新此文档以反映业务对数据的新的了解。